QC and downstream analysis for differential expression RNA-seq
Lorena Pantano
13 September 2019
DEGreport.RmdAbstract
DEGreport package version: 1.21.2Lorena Pantano Harvard TH Chan School of Public Health, Boston, US
General QC figures from DE analysis
We are going to do a differential expression analysis with edgeR/DESeq2. We have an object that is coming from the edgeR package. It contains a gene count matrix for 85 TSI HapMap individuals, and the gender information. With that, we are going to apply the glmFit function or DESeq2 to get genes differentially expressed between males and females.
library(DESeq2)
idx <- c(1:10, 75:85)
dds <- DESeqDataSetFromMatrix(assays(humanGender)[[1]][1:1000, idx],
colData(humanGender)[idx,], design=~group)
dds <- DESeq(dds)
res <- results(dds)We need to extract the experiment design data.frame where the condition is Male or Female.
Size factor QC
A main assumption in library size factor calculation of edgeR and DESeq2 (and others) is that the majority of genes remain unchanged. Plotting the distribution of gene ratios between each gene and the average gene can show how true this is. Not super useful for many samples because the plot becomes crowed.
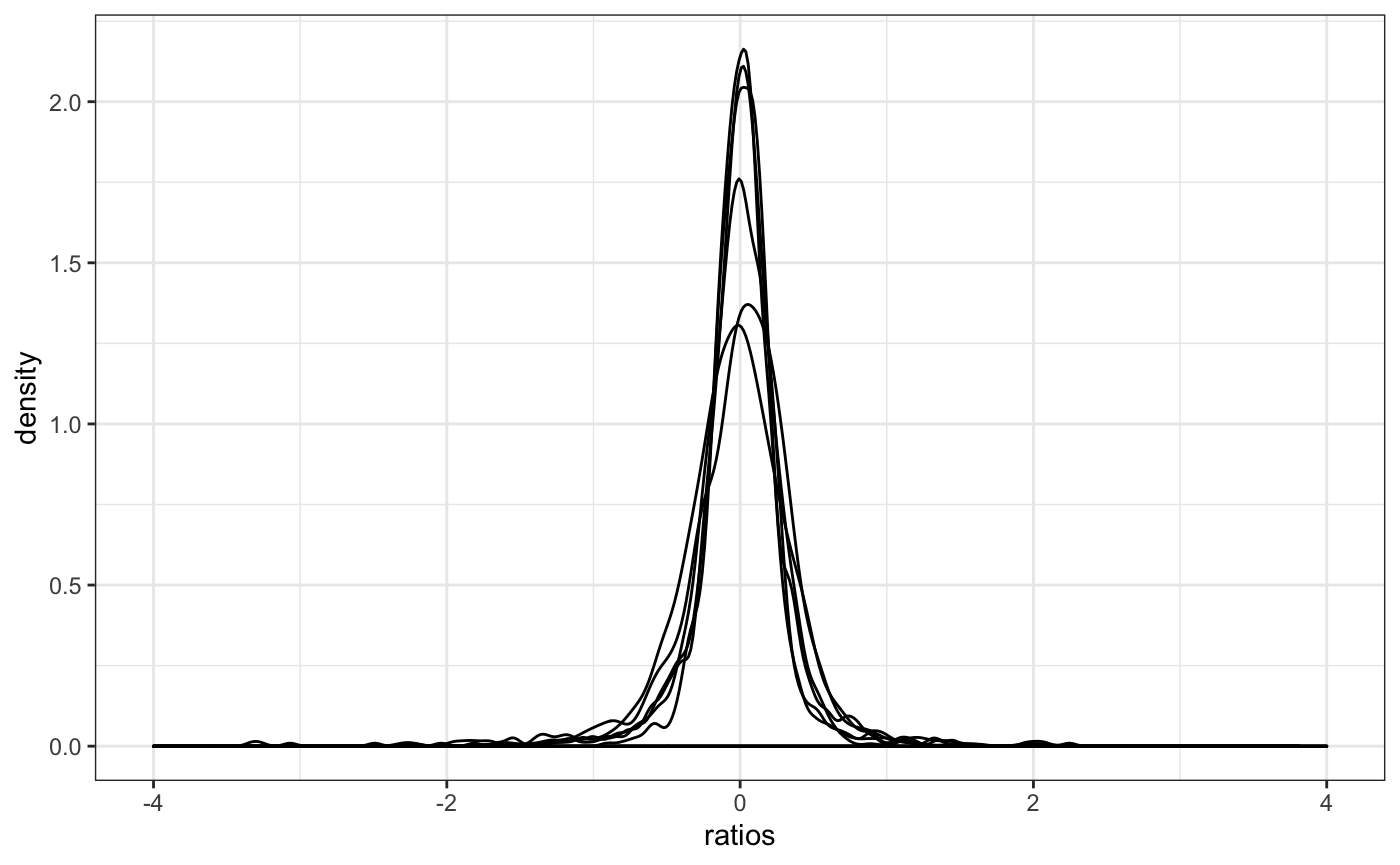
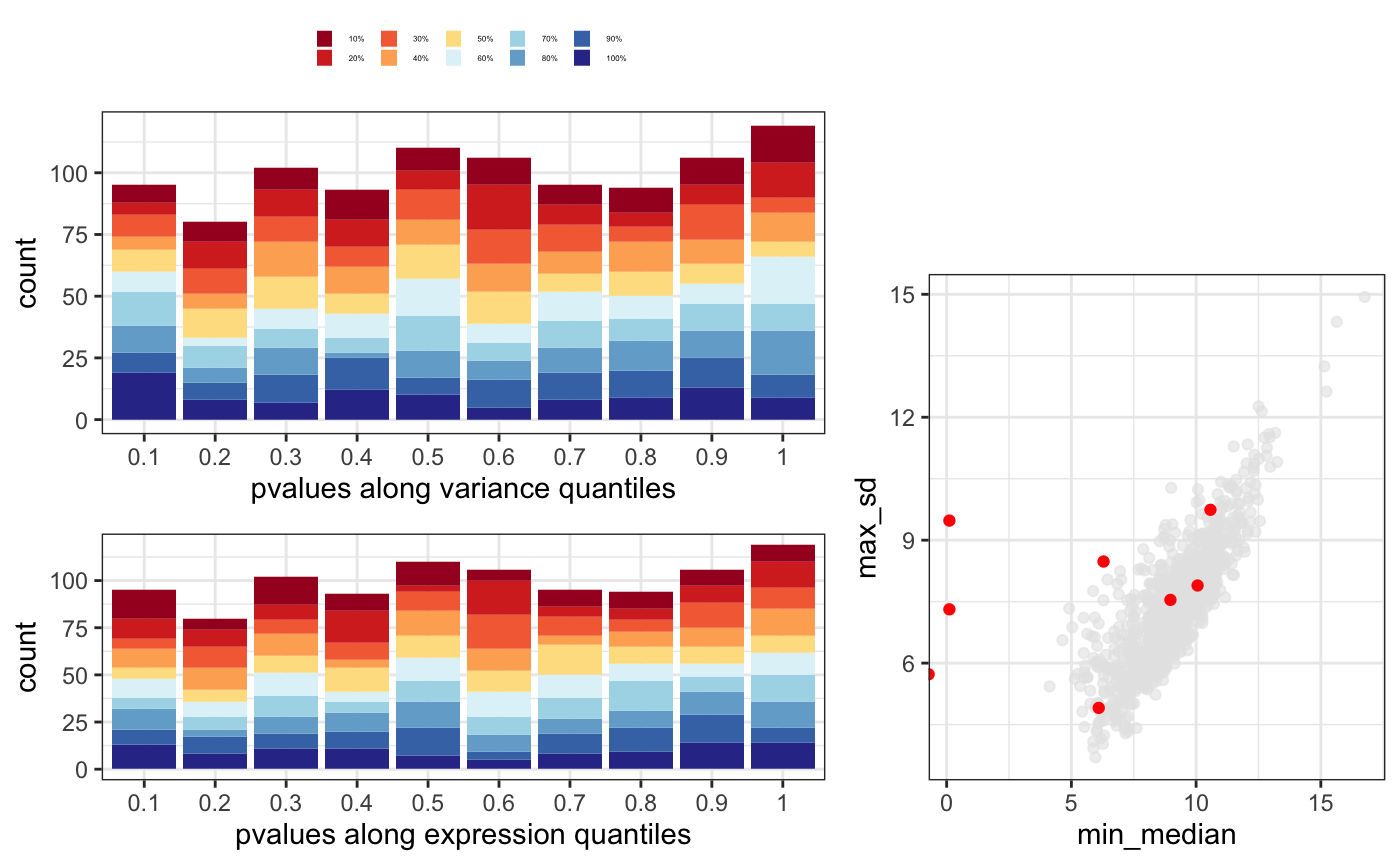
Mean-Variance QC plots
p-value distribution gives an idea on how well you model is capturing the input data and as well whether it could be some problem for some set of genes. In general, you expect to have a flat distribution with peaks at 0 and 1. In this case, we add the mean count information to check if any set of genes are enriched in any specific p-value range.
Variation (dispersion) and average expression relationship shouldn’t be a factor among the differentially expressed genes. When plotting average mean and standard deviation, significant genes should be randomly distributed.
In this case, it would be good to look at the ones that are totally outside the expected correlation.
You can put this tree plots together using degQC.
Covariates effect on count data
Another important analysis to do if you have covariates is to calculate the correlation between PCs from PCA analysis to different variables you may think are affecting the gene expression. This is a toy example of how the function works with raw data, where clearly library size correlates with some of the PCs.
## Warning: Unquoting language objects with `!!!` is deprecated as of rlang 0.4.0.
## Please use `!!` instead.
##
## # Bad:
## dplyr::select(data, !!!enquo(x))
##
## # Good:
## dplyr::select(data, !!enquo(x)) # Unquote single quosure
## dplyr::select(data, !!!enquos(x)) # Splice list of quosures
##
## This warning is displayed once per session.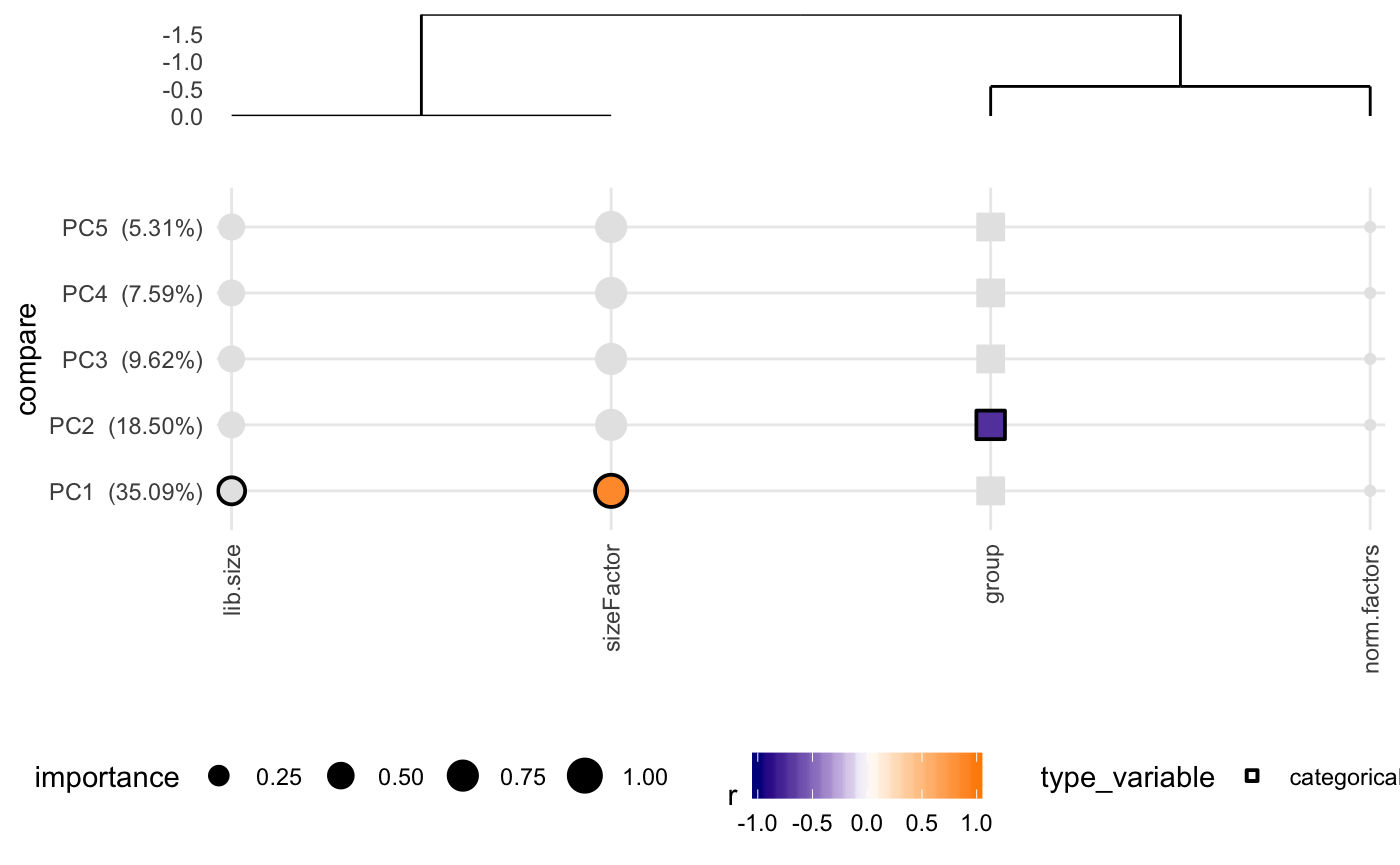
Covariates correlation with metrics
Also, the correlation among covariates and metrics from the analysis can be tested. This is useful when the study has multiple variables, like in clinical trials. The following code will return a correlation table, and plot the correlation heatmap for all the covariates and metrics in a table.
## Warning: The input is a data frame, convert it to the matrix.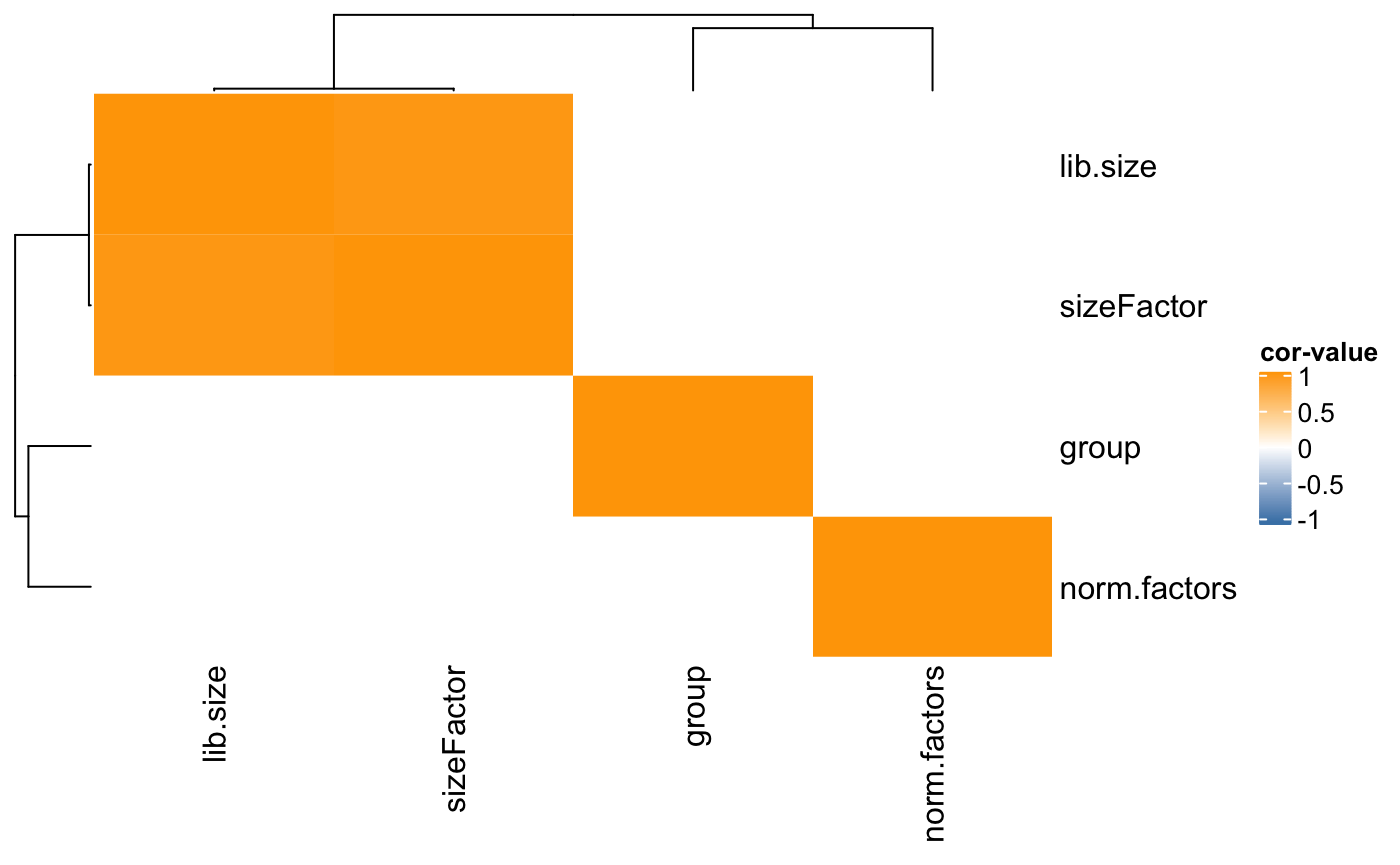
## [1] "cor" "corMat" "fdrMat" "plot"Report from DESeq2 analysis
Here, we show some useful plots for differentially expressed genes.
Contrasts
DEGSet is a class to store the DE results like the one from results function. DESeq2 offers multiple way to ask for contrasts/coefficients. With degComps is easy to get multiple results in a single object:
degs <- degComps(dds, combs = "group",
contrast = list("group_Male_vs_Female",
c("group", "Female", "Male")))
names(degs)## [1] "group_Male_vs_Female" "group_Female_vs_Male"degs contains 3 elements, one for each contrast/coefficient asked for. It contains the results output in the element raw and the output of lfcShrink in the element shrunken. To obtain the results from one of them, use the method dge:
## log2 fold change (MAP): group Male vs Female
## Wald test p-value: group Male vs Female
## DataFrame with 1000 rows and 6 columns
## baseMean log2FoldChange lfcSE
## <numeric> <numeric> <numeric>
## ENSG00000067048 1025.03783081851 1.93948751981499 0.100694015277881
## ENSG00000012817 411.543865988588 3.70056395376914 0.0989888483685399
## ENSG00000067646 169.814765626402 3.32284568660182 0.0995193327364425
## ENSG00000005889 670.861906530697 -0.489434740758987 0.0929363099393882
## ENSG00000006757 92.6611112908156 -0.472926180708215 0.0992749166821474
## ... ... ... ...
## ENSG00000068120 1214.09670077803 -0.000114321924521797 0.0797226606999419
## ENSG00000072062 935.317212058596 0.000559219142042473 0.0915352171745645
## ENSG00000076770 1019.79638067687 0.000850081845596963 0.101666325101382
## ENSG00000078967 166.422097051996 0.000415745391577556 0.0959757955312274
## ENSG00000079246 5226.33895971623 0.000149584255112998 0.0926205100248815
## stat pvalue
## <numeric> <numeric>
## ENSG00000067048 23.9943800011738 3.18302039220984e-127
## ENSG00000012817 21.8045168852374 2.1021393959939e-105
## ENSG00000067646 15.483847327858 4.45984434297296e-54
## ENSG00000005889 -5.26370810368132 1.41178536870766e-07
## ENSG00000006757 -4.7570056960935 1.96485627341685e-06
## ... ... ...
## ENSG00000068120 -0.00143399782359433 0.998855835668463
## ENSG00000072062 0.00610871981311817 0.995125977088406
## ENSG00000076770 0.00836192966138066 0.993328223175271
## ENSG00000078967 0.00432971042060565 0.996545401696197
## ENSG00000079246 0.00161499511898696 0.998711420888936
## padj
## <numeric>
## ENSG00000067048 3.18302039220984e-124
## ENSG00000012817 1.05106969799695e-102
## ENSG00000067646 1.48661478099099e-51
## ENSG00000005889 3.52946342176915e-05
## ENSG00000006757 0.00039297125468337
## ... ...
## ENSG00000068120 0.998855835668463
## ENSG00000072062 0.998855835668463
## ENSG00000076770 0.998855835668463
## ENSG00000078967 0.998855835668463
## ENSG00000079246 0.998855835668463## <numeric>
## 1025.03783081851
## 411.543865988588
## 169.814765626402
## 670.861906530697
## 92.6611112908156
## ...
## 1214.09670077803
## 935.317212058596
## 1019.79638067687
## 166.422097051996
## 5226.33895971623
## <numeric>
## 1.93948751981499
## 3.70056395376914
## 3.32284568660182
## -0.489434740758987
## -0.472926180708215
## ...
## -0.000114321924521797
## 0.000559219142042473
## 0.000850081845596963
## 0.000415745391577556
## 0.000149584255112998
## <numeric>
## 0.100694015277881
## 0.0989888483685399
## 0.0995193327364425
## 0.0929363099393882
## 0.0992749166821474
## ...
## 0.0797226606999419
## 0.0915352171745645
## 0.101666325101382
## 0.0959757955312274
## 0.0926205100248815
## <numeric>
## 23.9943800011738
## 21.8045168852374
## 15.483847327858
## -5.26370810368132
## -4.7570056960935
## ...
## -0.00143399782359433
## 0.00610871981311817
## 0.00836192966138066
## 0.00432971042060565
## 0.00161499511898696
## <numeric>
## 3.18302039220984e-127
## 2.1021393959939e-105
## 4.45984434297296e-54
## 1.41178536870766e-07
## 1.96485627341685e-06
## ...
## 0.998855835668463
## 0.995125977088406
## 0.993328223175271
## 0.996545401696197
## 0.998711420888936
## <numeric>
## 3.18302039220984e-124
## 1.05106969799695e-102
## 1.48661478099099e-51
## 3.52946342176915e-05
## 0.00039297125468337
## ...
## 0.998855835668463
## 0.998855835668463
## 0.998855835668463
## 0.998855835668463
## 0.998855835668463By default it would output the shrunken table always, as defined by degDefault, that contains the default table to get.
To get the original results table, use the parameter as this:
## # A tibble: 1,000 x 7
## gene baseMean log2FoldChange lfcSE stat pvalue padj
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 ENSG00000067048 1025. 10.2 0.423 24.0 3.18e-127 3.18e-124
## 2 ENSG00000012817 412. 9.24 0.424 21.8 2.10e-105 1.05e-102
## 3 ENSG00000067646 170. 10.2 0.658 15.5 4.46e- 54 1.49e- 51
## 4 ENSG00000005889 671. -0.692 0.131 -5.26 1.41e- 7 3.53e- 5
## 5 ENSG00000006757 92.7 -0.767 0.161 -4.76 1.96e- 6 3.93e- 4
## 6 ENSG00000073282 220. -1.87 0.421 -4.44 8.89e- 6 1.48e- 3
## 7 ENSG00000005302 2027. -0.742 0.176 -4.21 2.59e- 5 3.69e- 3
## 8 ENSG00000005020 1234. 0.389 0.0952 4.08 4.44e- 5 5.56e- 3
## 9 ENSG00000003400 394. 0.680 0.177 3.85 1.17e- 4 1.31e- 2
## 10 ENSG00000069702 107. -1.63 0.459 -3.56 3.71e- 4 3.71e- 2
## # … with 990 more rowsNote that the format of the output can be changed to tibble, or data.frame with a third parameter tidy.
The table will be always sorted by padj.
And easy way to get significant genes is:
## [1] "ENSG00000012817" "ENSG00000067646" "ENSG00000067048"
## [4] "ENSG00000005889" "ENSG00000006757" "ENSG00000005302"
## [7] "ENSG00000003400" "ENSG00000073282" "ENSG00000005020"
## [10] "ENSG00000069702"This function can be used as well for a list of comparisons:
## [1] "ENSG00000012817" "ENSG00000067646" "ENSG00000067048"
## [4] "ENSG00000005889" "ENSG00000006757" "ENSG00000005302"
## [7] "ENSG00000003400" "ENSG00000073282" "ENSG00000005020"
## [10] "ENSG00000069702"And it can returns the full table for a list:
## # A tibble: 10 x 7
## gene log2FoldChange padj log2FoldChange_… log2FoldChange_…
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 ENSG… 0.388 1.31e- 2 -0.494 0.388
## 2 ENSG… 0.319 5.56e- 3 -0.351 0.319
## 3 ENSG… 0.541 3.69e- 3 0.541 -0.425
## 4 ENSG… 0.573 3.53e- 5 0.573 -0.489
## 5 ENSG… 0.585 3.93e- 4 0.585 -0.473
## 6 ENSG… 3.70 1.05e-102 -5.01 3.70
## 7 ENSG… 1.94 3.18e-124 -3.63 1.94
## 8 ENSG… 3.32 1.49e- 51 -4.43 3.32
## 9 ENSG… 0.453 3.71e- 2 0.453 -0.260
## 10 ENSG… 0.582 1.48e- 3 0.582 -0.339
## # … with 2 more variables: padj_group_Female_vs_Male <dbl>,
## # padj_group_Male_vs_Female <dbl>Since log2FoldChange are shrunken, the method for DEGSet class now can plot these changes as follow:
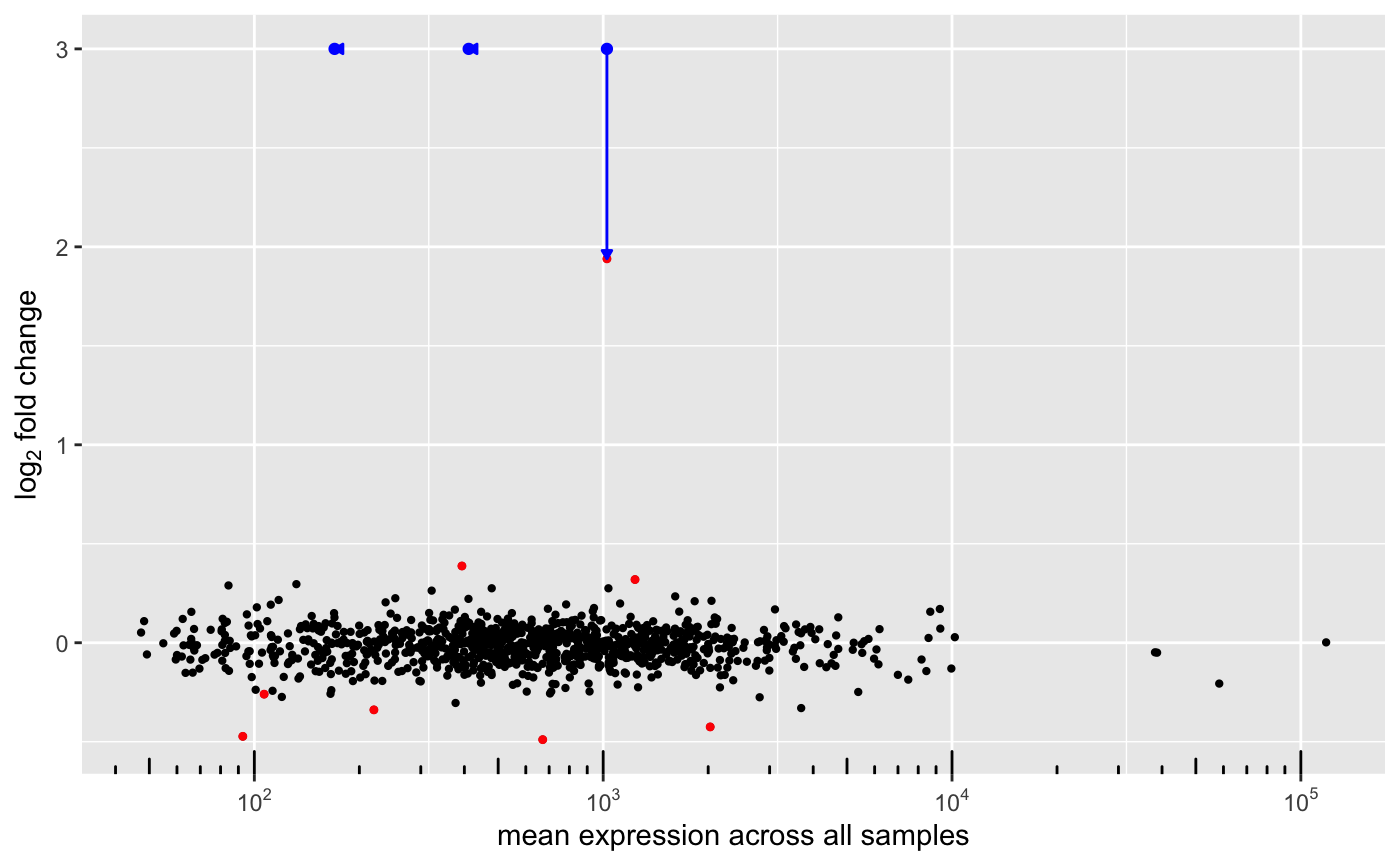
The blue arrows indicate how foldchange is affected by this new feature.
As well, it can plot the original MA plot:
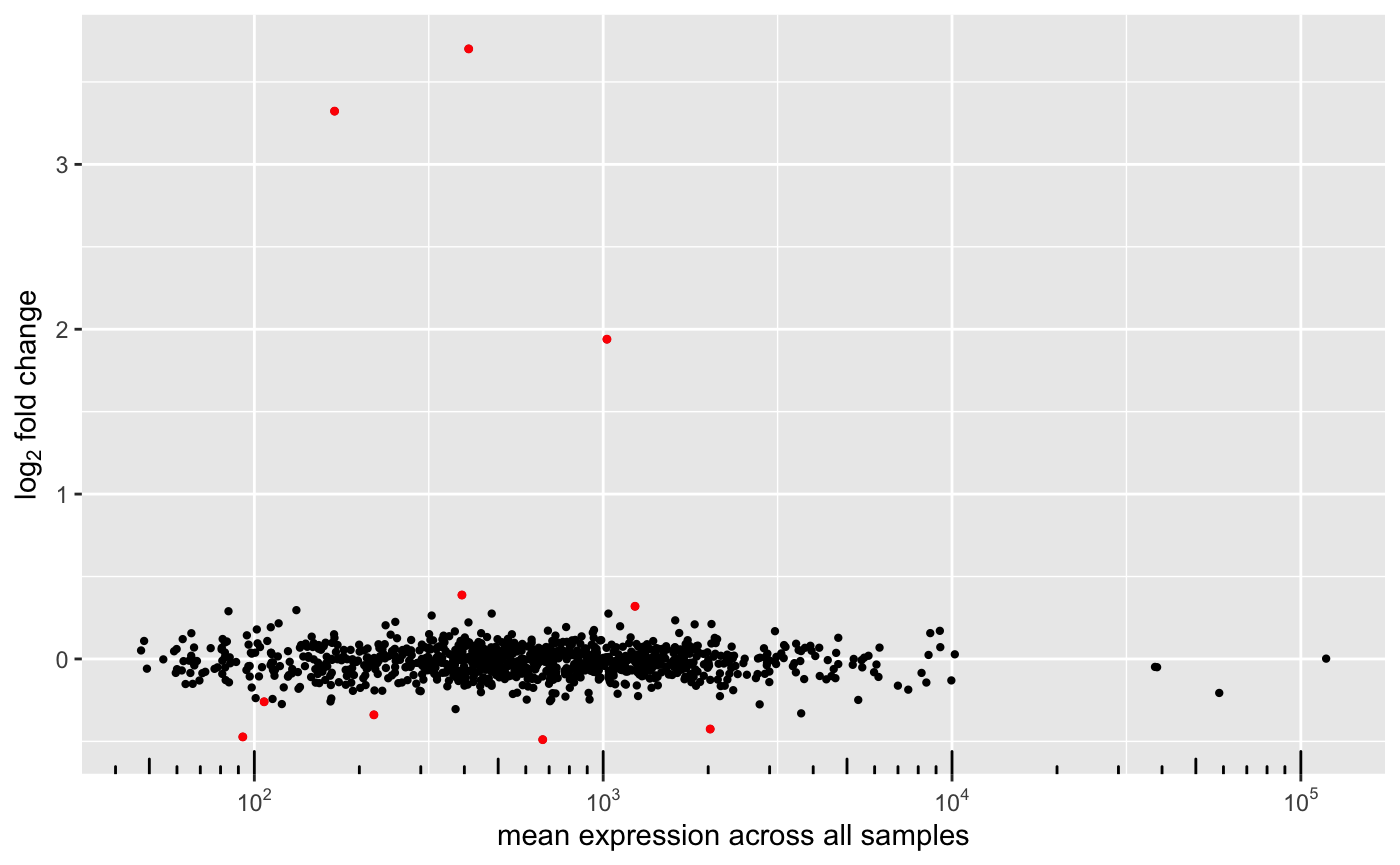
or the correlation between the original log2FoldChange and the new ones:
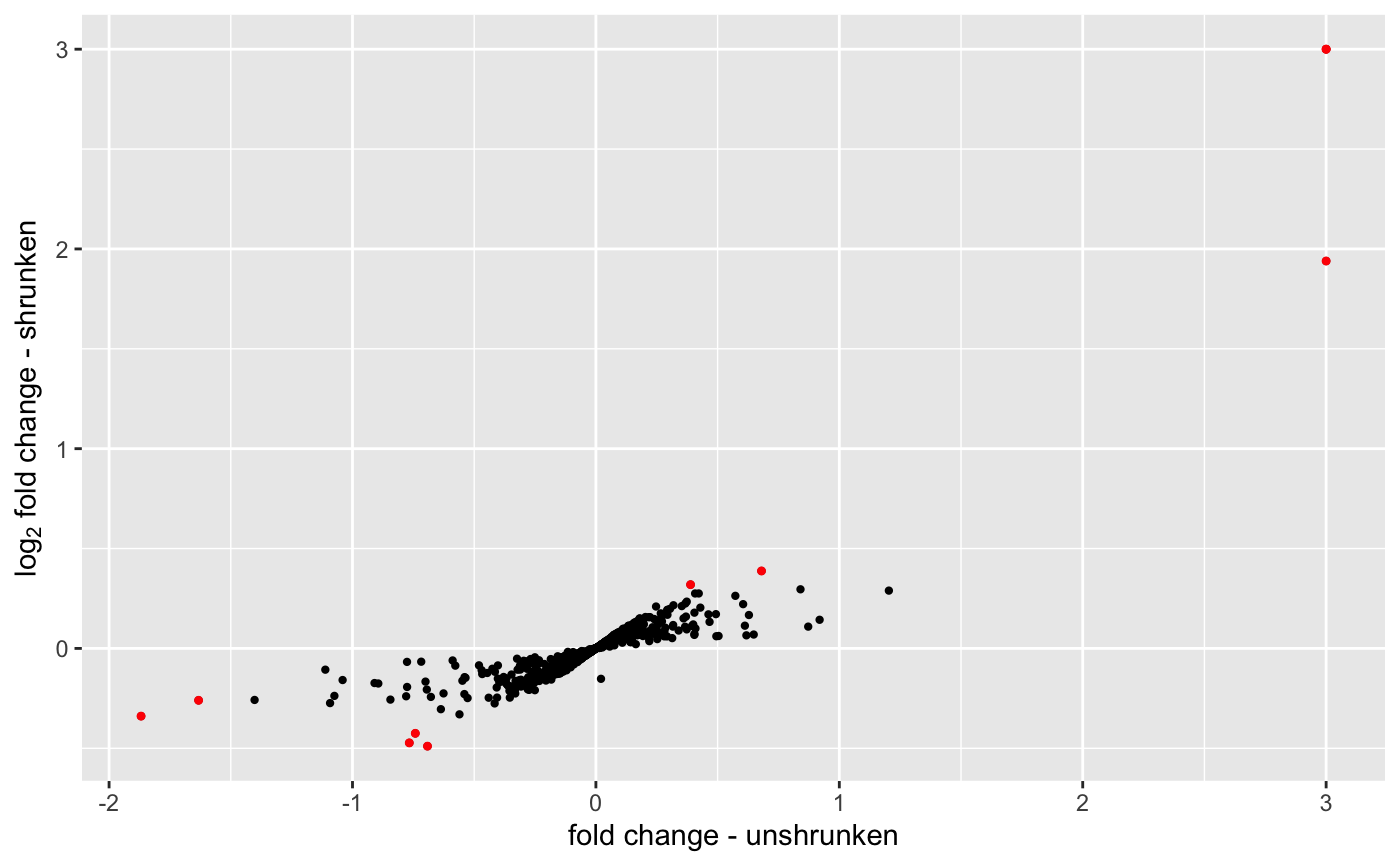
Volcano plots
Volcano plot using the output of DESeq2. It mainly needs data.frame with two columns (logFC and pVal). Specific genes can be plot using the option plot\_text (subset of the previous data.frame with a 3rd column to be used to plot the gene name).
res[["id"]] <- row.names(res)
show <- as.data.frame(res[1:10, c("log2FoldChange", "padj", "id")])
degVolcano(res[,c("log2FoldChange", "padj")], plot_text = show)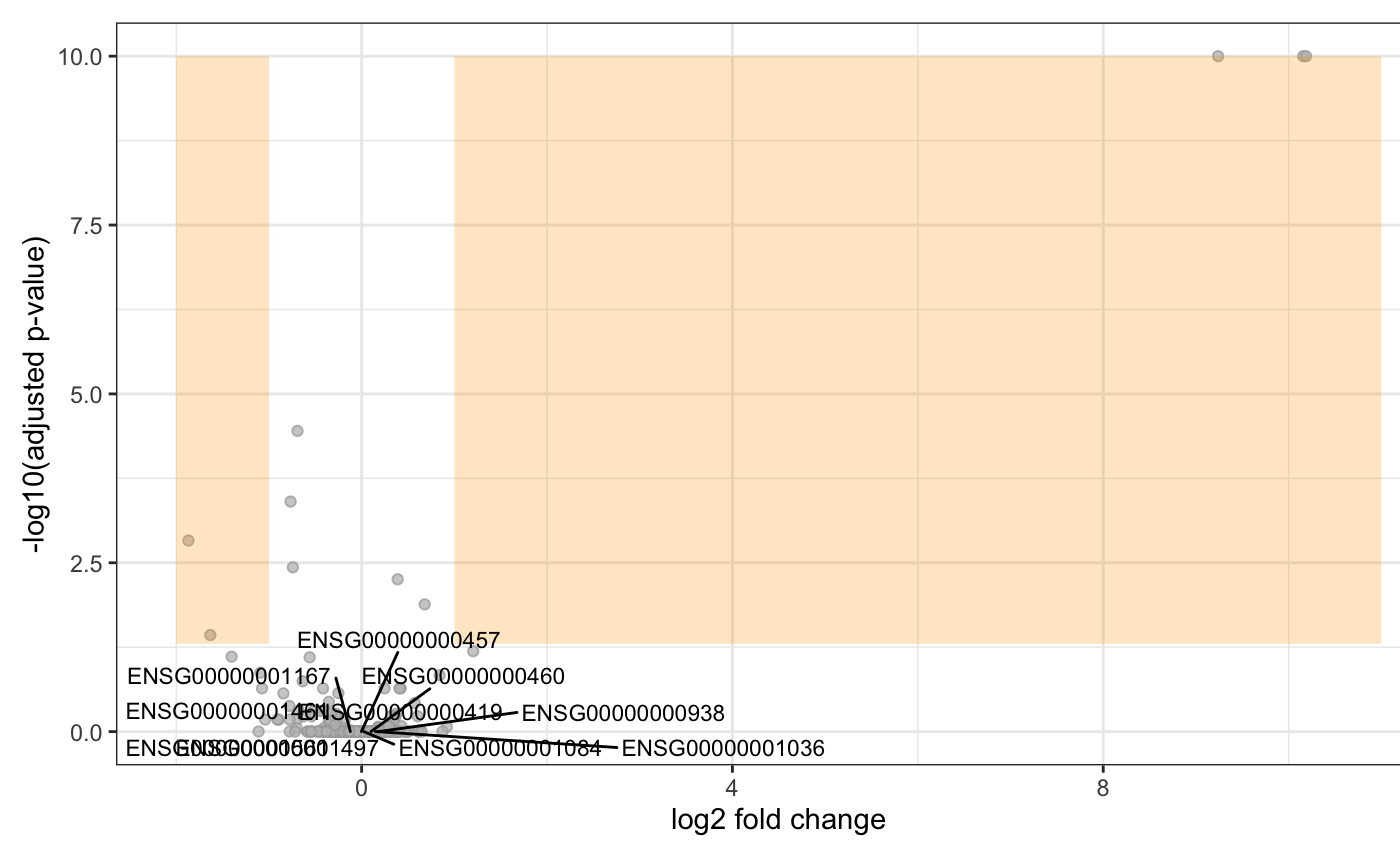
Note that the function is compatible with DEGset. Using degVolcano(degs[[1]]) is valid.
Gene plots
Plot top genes coloring by group. Very useful for experiments with nested groups. xs can be time or WT/KO, and group can be treated/untreated. Another classification can be added, like batch that will plot points with different shapes.
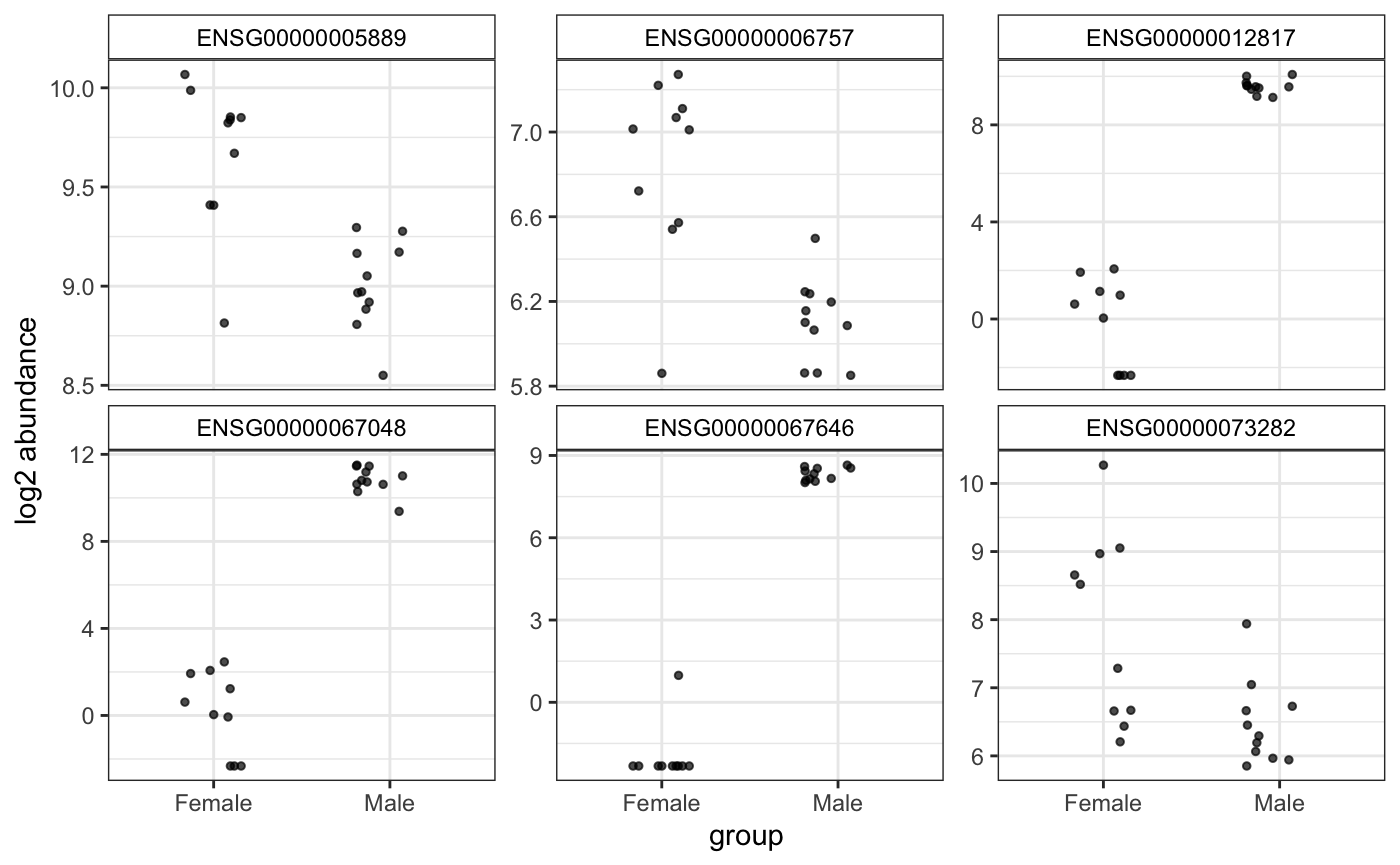
Another option for plotting genes in a wide format:
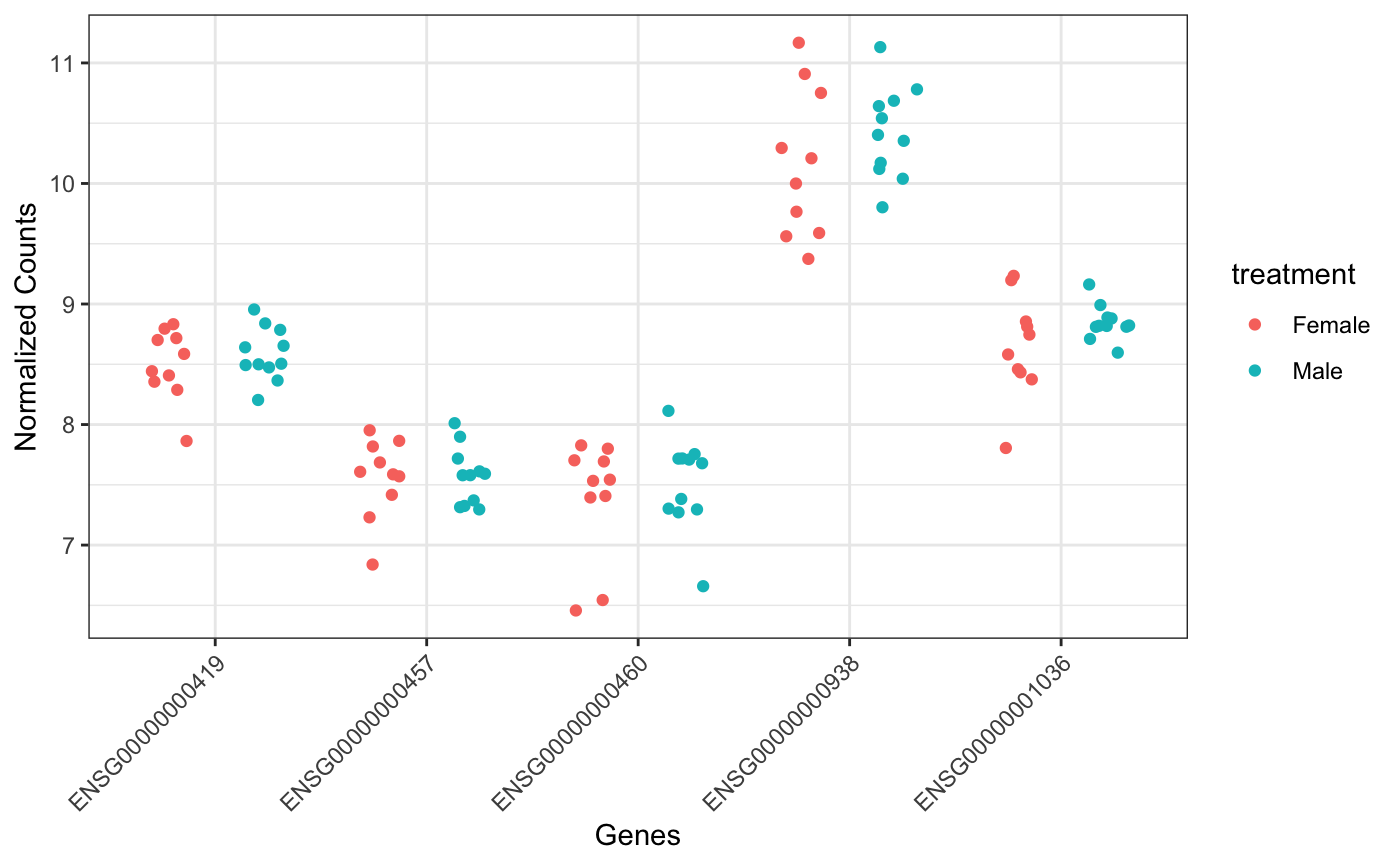
Markers plots
Markers can be used to show whether different conditions are enriched in different markers. For instance, in this example, Females and Males show different total expression for chromosome X/Y markers
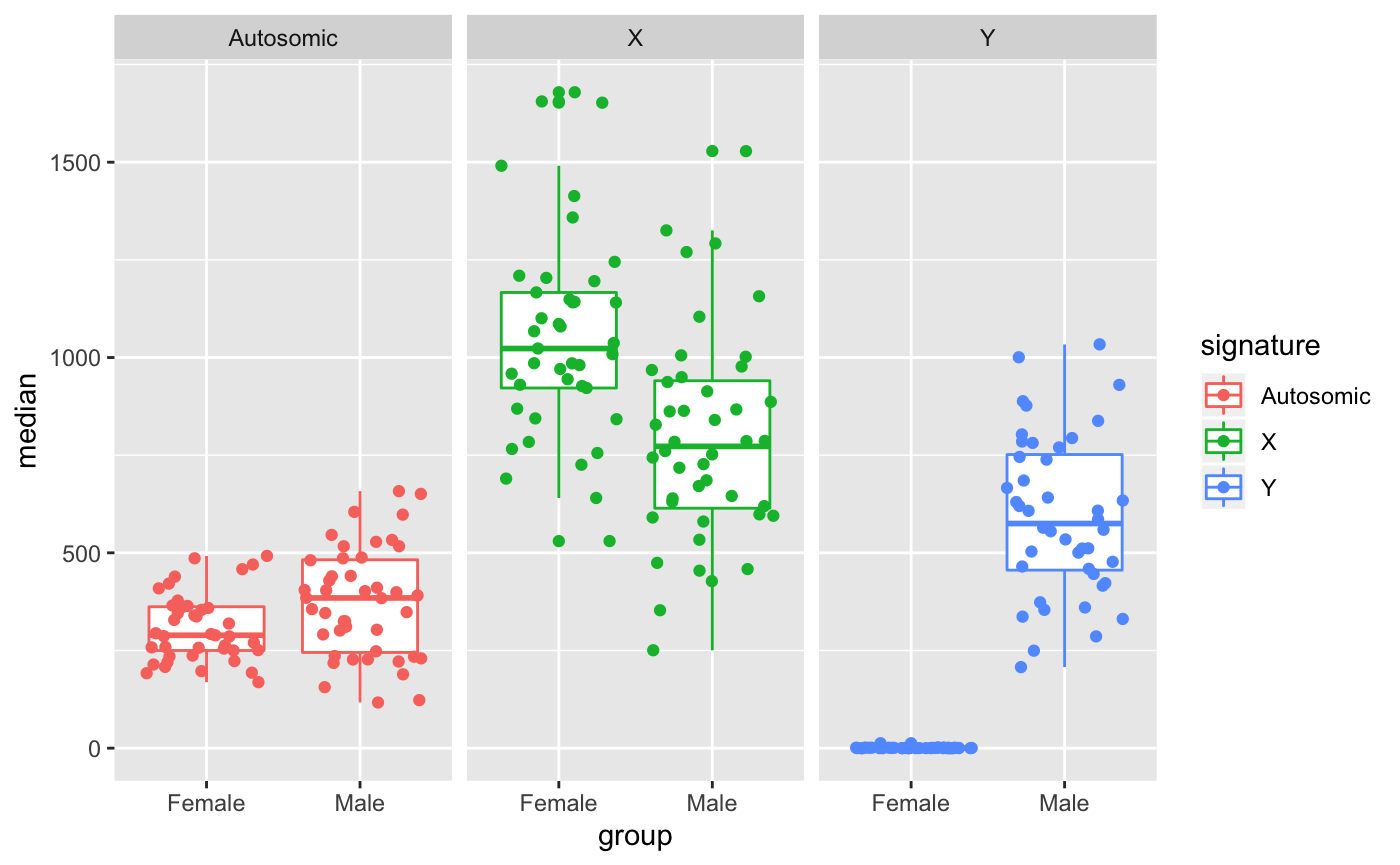
Full report
If you have a DESeq2 object, you can use degResults to create a full report with markdown code inserted, including figures and table with top de-regulated genes, GO enrichment analysis and heatmaps and PCA plots. If you set , different files will be saved there.
resreport <- degResults(dds = dds, name = "test", org = NULL,
do_go = FALSE, group = "group", xs = "group",
path_results = NULL)## ## Comparison: test {.tabset}
##
##
## [1] "DESeqResults object of length 6 with 2 metadata columns"<br>[2] NA <br>[3] NA <br>[4] NA <br>[5] NA <br>[6] NA <br>[7] NA <br>[8] NA
##
##
## Differential expression file at: test_de.csv
##
## Normalized counts matrix file at: test_log2_counts.csv
##
## ### MA plot plot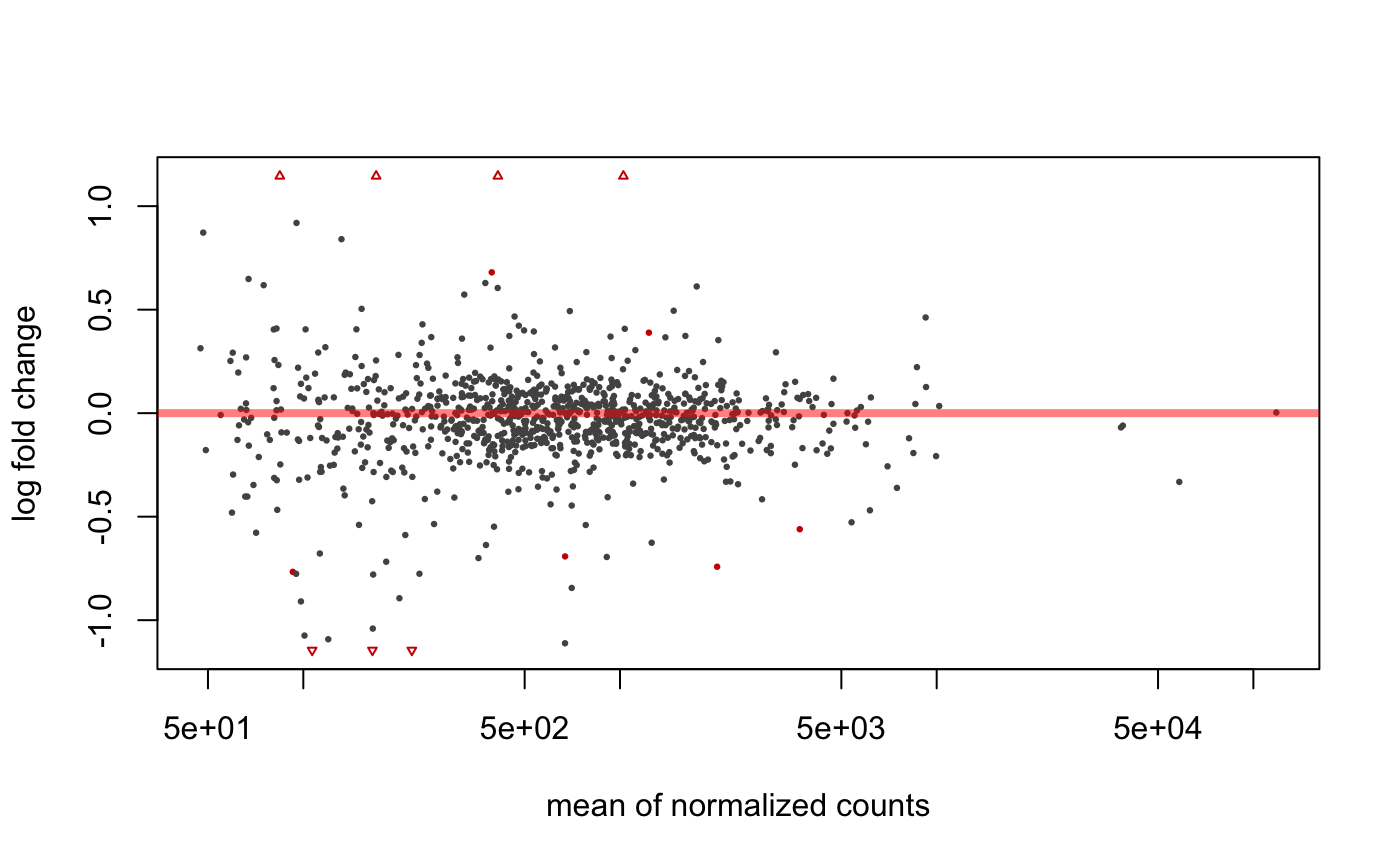
##
##
## ### Volcano plot
##
##
##
## ### QC for DE genes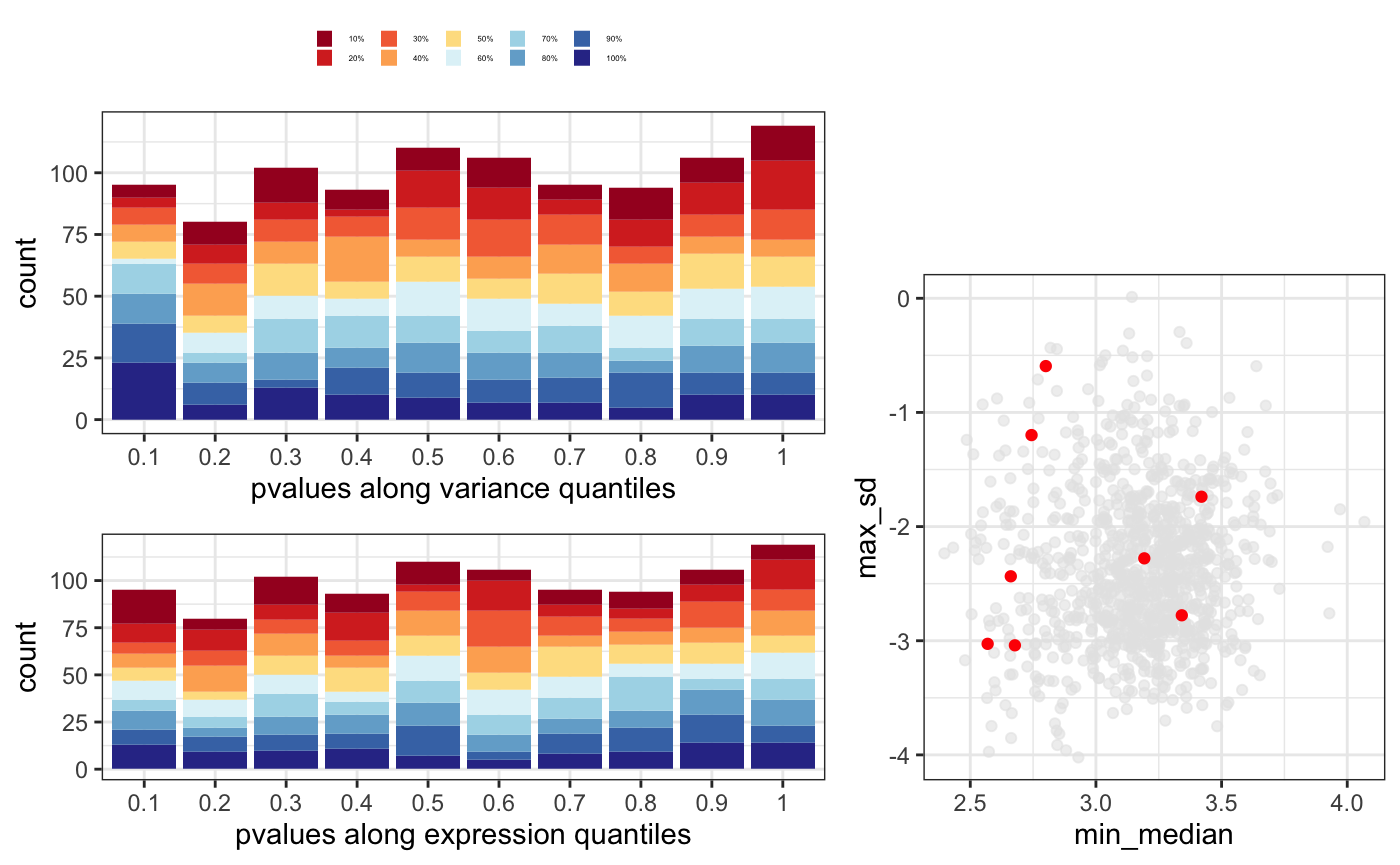
##
##
## ### Most significants, FDR< 0.05 and log2FC > 0.1 : 10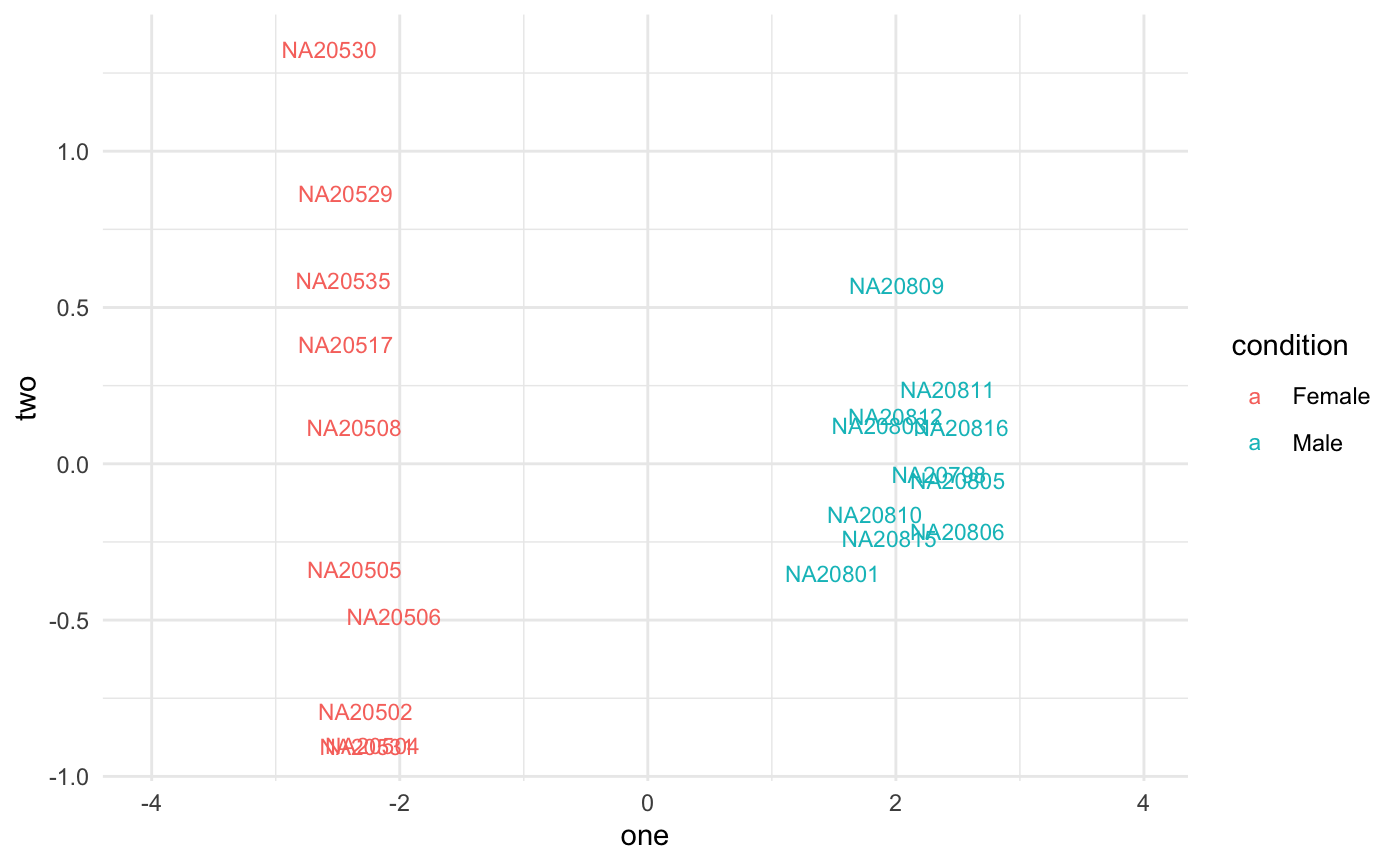
##
##
##
## ### Plots top 9 most significants
##
##
##
## ### Top DE table
##
##
##
## baseMean log2FoldChange lfcSE stat pvalue padj absMaxLog2FC
## ---------------- ----------- --------------- ---------- ---------- ---------- ---------- -------------
## ENSG00000067048 1025.03783 10.1571705 0.4233146 23.994380 0.0000000 0.0000000 10.1571705
## ENSG00000012817 411.54387 9.2394007 0.4237379 21.804517 0.0000000 0.0000000 9.2394007
## ENSG00000067646 169.81477 10.1874916 0.6579432 15.483847 0.0000000 0.0000000 10.1874916
## ENSG00000005889 670.86191 -0.6919265 0.1314523 -5.263708 0.0000001 0.0000353 0.6919265
## ENSG00000006757 92.66111 -0.7666012 0.1611520 -4.757006 0.0000020 0.0003930 0.7666012
## ENSG00000073282 220.15603 -1.8685615 0.4206120 -4.442482 0.0000089 0.0014821 1.8685615
## ENSG00000005302 2026.54990 -0.7418952 0.1763412 -4.207157 0.0000259 0.0036943 0.7418952
## ENSG00000005020 1233.86316 0.3888370 0.0952312 4.083085 0.0000444 0.0055552 0.3888370
## ENSG00000003400 393.62677 0.6803243 0.1766475 3.851310 0.0001175 0.0130542 0.6803243
## ENSG00000069702 106.67010 -1.6323189 0.4585611 -3.559654 0.0003713 0.0371343 1.6323189
## ENSG00000010278 84.30823 1.2035871 0.3554857 3.385754 0.0007098 0.0645300 1.2035871
## ENSG00000023171 165.31692 -1.4022259 0.4236024 -3.310240 0.0009322 0.0776799 1.4022259
## ENSG00000072501 3694.76013 -0.5604815 0.1707989 -3.281529 0.0010325 0.0794200 0.5604815
## ENSG00000070018 119.89049 -1.0921227 0.3512409 -3.109327 0.0018751 0.1339388 1.0921227
## ENSG00000059377 131.98111 0.8405094 0.2744635 3.062372 0.0021959 0.1463935 0.8405094
## ENSG00000008277 377.43955 -0.6368732 0.2136506 -2.980910 0.0028739 0.1796208 0.6368732
## ENSG00000005059 479.12528 0.4225402 0.1492246 2.831571 0.0046320 0.2289281 0.4225402
## ENSG00000012963 1829.21224 0.2471040 0.0861859 2.867104 0.0041425 0.2289281 0.2471040
## ENSG00000038427 100.87217 -1.0743654 0.3810269 -2.819658 0.0048075 0.2289281 1.0743654
## ENSG00000068079 1035.17996 0.4075632 0.1415563 2.879160 0.0039874 0.2289281 0.4075632Detect patterns of expression
In this section, we show how to detect pattern of expression. Mainly useful when data is a time course experiment. degPatterns needs a expression matrix, the design experiment and the column used to group samples.
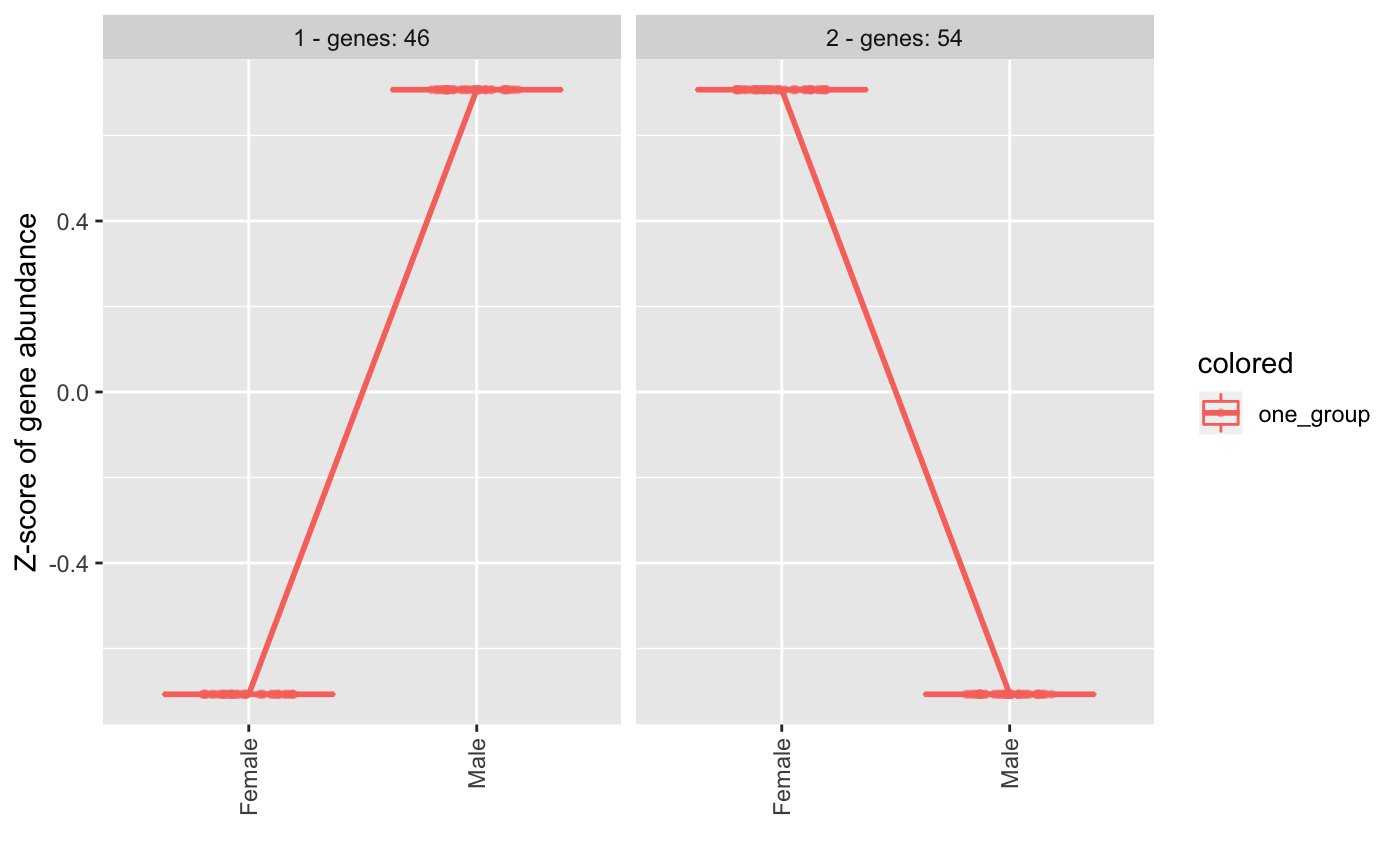
Useful functions
This section shows some useful functions during DEG analysis.
Filter genes by group
degFilter helps to filter genes with a minimum read count by group.
gene in original count matrix: 1000
filter_count <- degFilter(counts(dds),
design, "group",
min=1, minreads = 50)
cat("gene in final count matrix", nrow(filter_count))gene in final count matrix 940
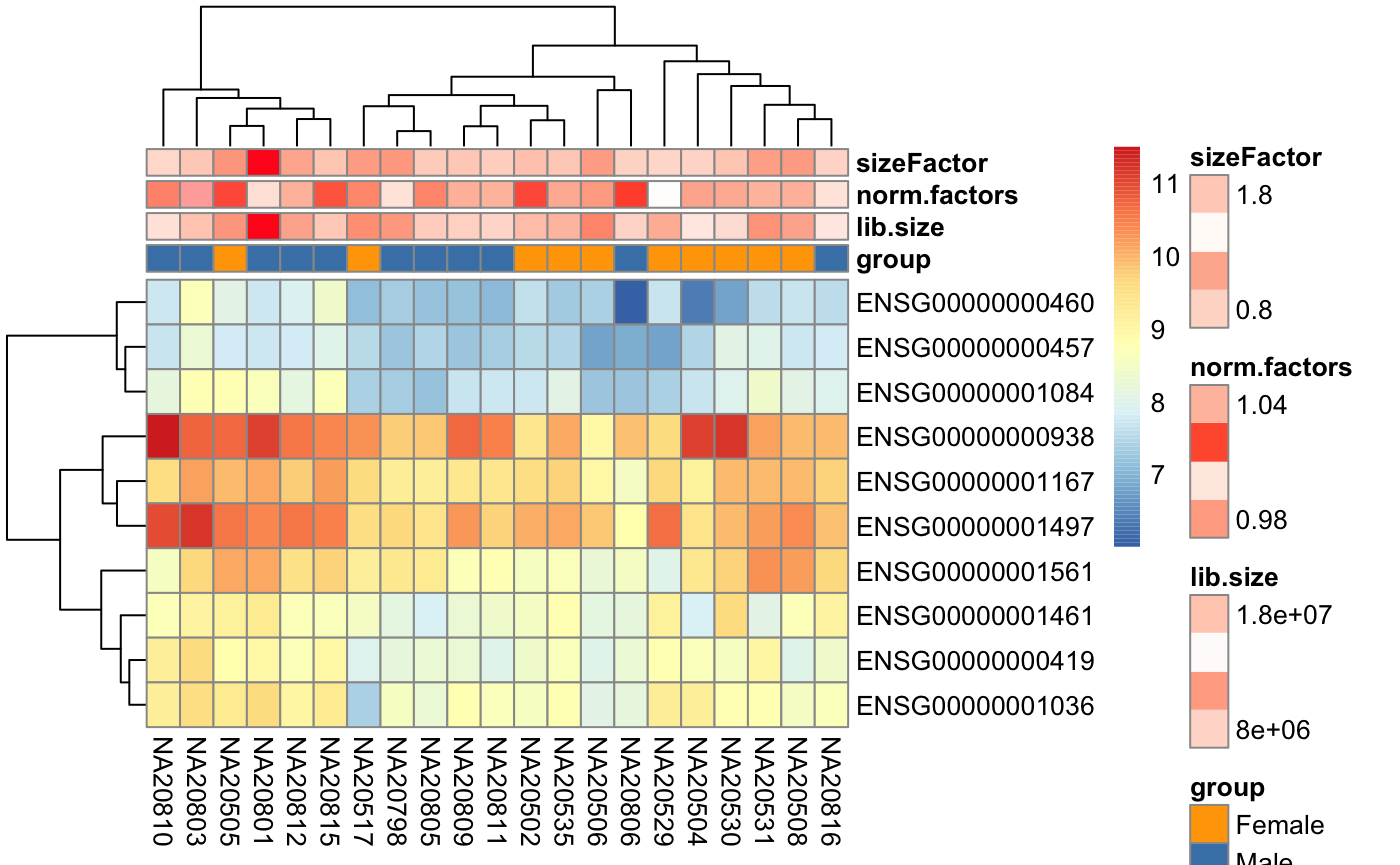
Generate colors for metadata variables
This functions allows you to create colors for metadata columns to be used as annotation for columns in a heatmap figure.
library(ComplexHeatmap)
th <- HeatmapAnnotation(df = colData(dds),
col = degColors(colData(dds), TRUE))
Heatmap(log2(counts(dds) + 0.5)[1:10,],
top_annotation = th)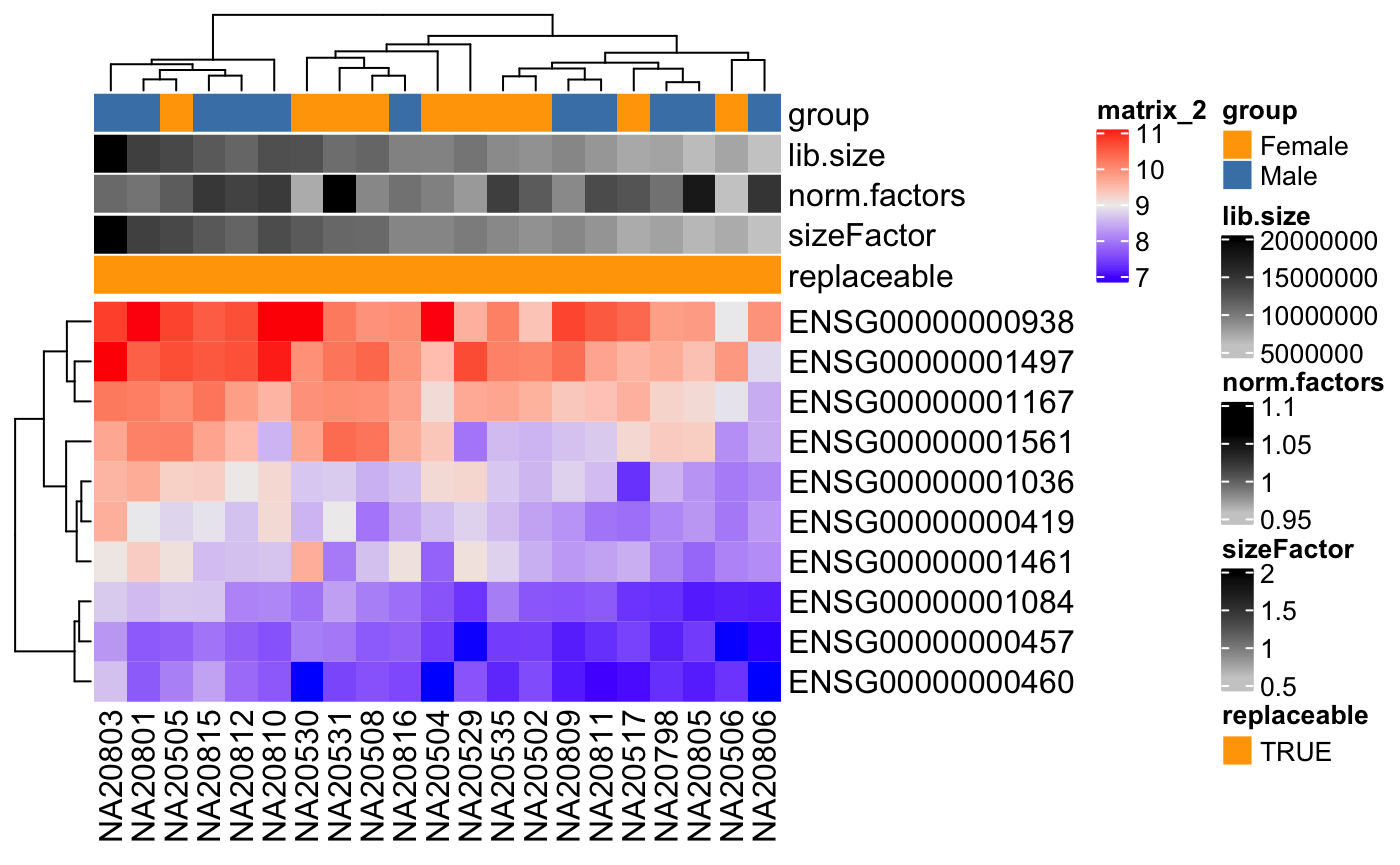
library(pheatmap)
pheatmap(log2(counts(dds) + 0.5)[1:10,],
annotation_col = as.data.frame(colData(dds))[,1:4],
annotation_colors = degColors(colData(dds)[1:4],
con_values = c("white",
"red")
)
)
Session info
## R version 3.6.1 (2019-07-05)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS Mojave 10.14.3
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
##
## attached base packages:
## [1] grid parallel stats4 stats graphics grDevices utils
## [8] datasets methods base
##
## other attached packages:
## [1] pheatmap_1.0.12 ComplexHeatmap_2.1.0
## [3] DESeq2_1.25.10 SummarizedExperiment_1.15.8
## [5] DelayedArray_0.11.4 BiocParallel_1.19.2
## [7] matrixStats_0.54.0 Biobase_2.45.0
## [9] GenomicRanges_1.37.15 GenomeInfoDb_1.21.1
## [11] IRanges_2.19.14 S4Vectors_0.23.20
## [13] BiocGenerics_0.31.5 DEGreport_1.21.2
## [15] BiocStyle_2.13.2
##
## loaded via a namespace (and not attached):
## [1] colorspace_1.4-1 rjson_0.2.20
## [3] rprojroot_1.3-2 circlize_0.4.7
## [5] htmlTable_1.13.1 XVector_0.25.0
## [7] ggdendro_0.1-20 GlobalOptions_0.1.0
## [9] base64enc_0.1-3 fs_1.3.1
## [11] clue_0.3-57 rstudioapi_0.10
## [13] ggrepel_0.8.1 bit64_0.9-7
## [15] fansi_0.4.0 AnnotationDbi_1.47.1
## [17] splines_3.6.1 logging_0.10-108
## [19] mnormt_1.5-5 geneplotter_1.63.0
## [21] knitr_1.24 zeallot_0.1.0
## [23] Formula_1.2-3 Nozzle.R1_1.1-1
## [25] broom_0.5.2 annotate_1.63.0
## [27] cluster_2.1.0 png_0.1-7
## [29] BiocManager_1.30.4 compiler_3.6.1
## [31] backports_1.1.4 assertthat_0.2.1
## [33] Matrix_1.2-17 lazyeval_0.2.2
## [35] cli_1.1.0 limma_3.41.15
## [37] lasso2_1.2-20 acepack_1.4.1
## [39] htmltools_0.3.6 tools_3.6.1
## [41] gtable_0.3.0 glue_1.3.1
## [43] GenomeInfoDbData_1.2.1 dplyr_0.8.3
## [45] Rcpp_1.0.2 pkgdown_1.4.0
## [47] vctrs_0.2.0 nlme_3.1-140
## [49] psych_1.8.12 xfun_0.9
## [51] stringr_1.4.0 XML_3.98-1.20
## [53] edgeR_3.27.13 zlibbioc_1.31.0
## [55] MASS_7.3-51.4 scales_1.0.0
## [57] RColorBrewer_1.1-2 yaml_2.2.0
## [59] memoise_1.1.0 gridExtra_2.3
## [61] ggplot2_3.2.1 rpart_4.1-15
## [63] reshape_0.8.8 latticeExtra_0.6-28
## [65] stringi_1.4.3 RSQLite_2.1.2
## [67] highr_0.8 genefilter_1.67.1
## [69] desc_1.2.0 checkmate_1.9.4
## [71] shape_1.4.4 rlang_0.4.0
## [73] pkgconfig_2.0.2 bitops_1.0-6
## [75] evaluate_0.14 lattice_0.20-38
## [77] purrr_0.3.2 labeling_0.3
## [79] htmlwidgets_1.3 cowplot_1.0.0
## [81] bit_1.1-14 tidyselect_0.2.5
## [83] plyr_1.8.4 magrittr_1.5
## [85] R6_2.4.0 generics_0.0.2
## [87] Hmisc_4.2-0 DBI_1.0.0
## [89] withr_2.1.2 pillar_1.4.2
## [91] foreign_0.8-71 survival_2.44-1.1
## [93] RCurl_1.95-4.12 nnet_7.3-12
## [95] tibble_2.1.3 crayon_1.3.4
## [97] utf8_1.1.4 fdrtool_1.2.15
## [99] rmarkdown_1.15 GetoptLong_0.1.7
## [101] locfit_1.5-9.1 data.table_1.12.2
## [103] blob_1.2.0 ConsensusClusterPlus_1.49.0
## [105] digest_0.6.20 xtable_1.8-4
## [107] tidyr_0.8.3 munsell_0.5.0